



Welcome back, everybody! I want to go more in-depth about the tech stack that I decided to use, and why I think it makes sense. You can also check out my deployed website here. We will also be going over the access patterns of the StackOverflow clone in order for us to smoothly code out all the functionality with a reliable blueprint.

According to this diagram, GraphQL acts as my server, and AppSync is the server manager that allows me to enact queries and mutations through the use of Lambda resolvers on my data in my DynamoDB tables. AppSync increases productivity because it handles the parsing and resolution of requests while connecting to other AWS services seamlessly, resulting in more time for the developer to focus on the actual code.
Using a GraphQL API instead of a regular REST API is beneficial because it prevents overfetching. When you make requests on GraphQL, you specify all the information that you need through your query and the response will follow the same structure of your schema.

In the diagram above, a REST API would return all the data that the specific user holds even though we would only want information regarding their questions.
Creating the Entity Relationship Diagram (ERD)
Before I get into the design of the ERD, I would strongly suggest that you get familiar with Alex DeBrie’s The DynamoDB Book. This resource has been extremely helpful in making sense of newer concepts that I haven’t encountered before. Everything I suggest moving forward will be a reflection of this book and my opinion.
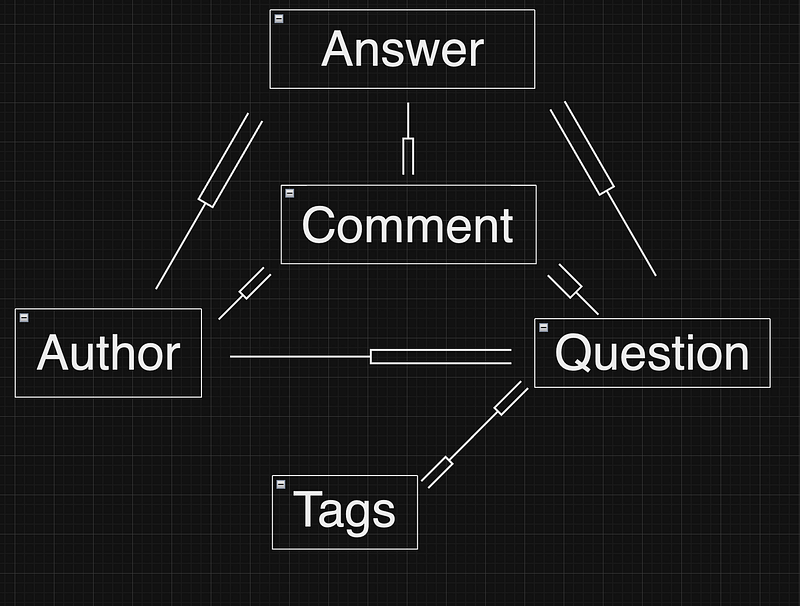
This diagram illustrates:
For each Author, there are many Questions, Answers, and Comments.
For each Question, there are many Answers, Comments, and Tags
For each Answer, there are many comments
For each Tag, there are many Questions
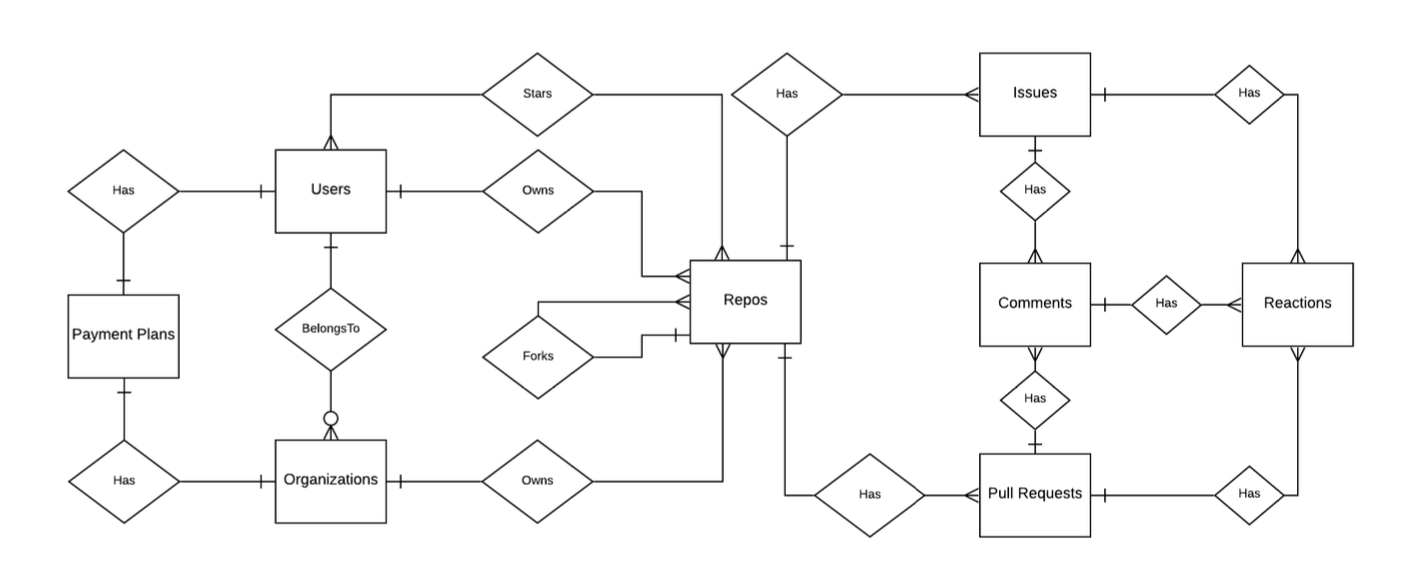
This is a relatively simple ERD, but these can get pretty complex. Here is an example of Github’s ERD:
Modeling Access Patterns
If we were using a relational database, we’d be able to ship our ERD right to the database. The entities will translate to tables and the relationships between them are configured by foreign keys. That is not the case when data modeling in DynamoDB. We would have to design our data to handle our specific access patterns. As a result, we need to be specific and thorough. Failure to do so may lead to problems down the line leading to a database with a lack of flexibility.
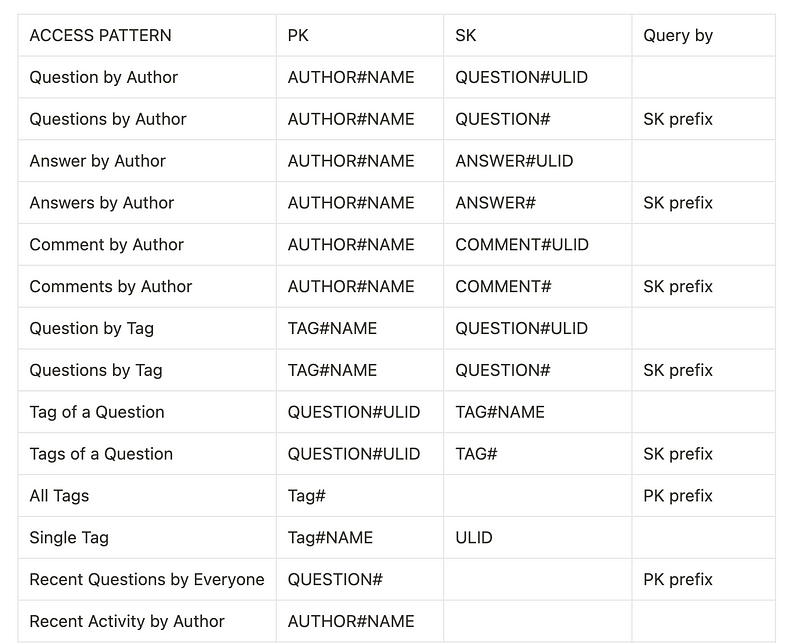
DynamoDB doesn't support Queries that return all of a certain entity because it is the antithesis of what DynamoDB prides itself in; scalability. DynamoDB does allow Scans but it is potentially costly in performance and consumed capacity units (price). Fortunately, the “Query by” column describes a way for us to receive all of a certain type of entity in a single partition. So to bypass this hurdle, our query parameter will contain a FilterExpression similar to this.
FilterExpression: "begins_with(#PK, :pk_prefix) AND begins_with(#SK, :sk_prefix)"
This will scan all items that have the specific PK and SK prefix such as AUTHOR#, QUESTION#, ANSWER#, etc.
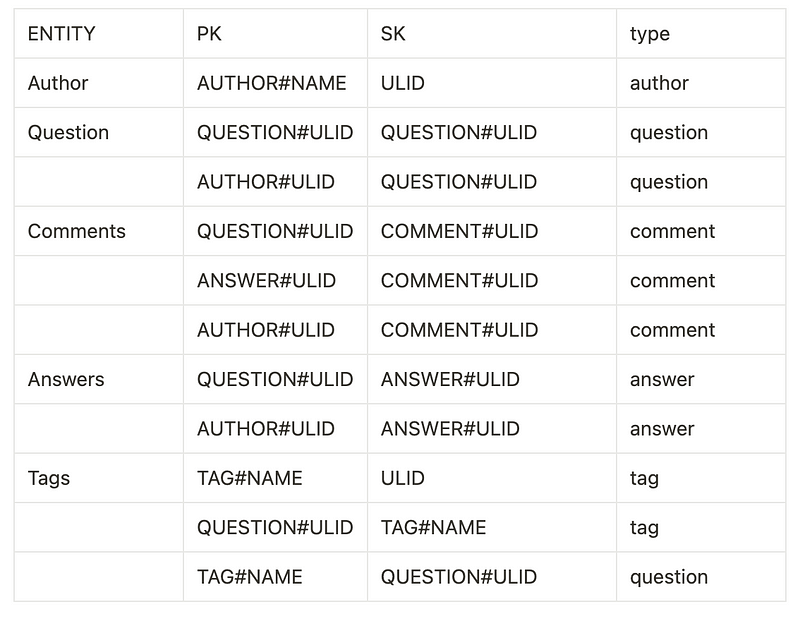
With the creation of these access patterns, I need to create a primary key structure that allows me to partition the data and sort it in a way that allows me to receive the information that I need.
Modeling the Primary Key Structure
If you refer to our ERD above while looking at this table, you will start to notice a pattern. Every entity (PK) that has a one-to-many relationship to another entity (SK) is listed in the table. Since we are going to be creating a DynamoDB table with a single-table design, our database will be flooded with many different items so we need to format our items in a way that promotes simple querying.
GraphQL Schema
To start, we want to have full CRUD functionality with the questions that we create. This is what the schema would look like:
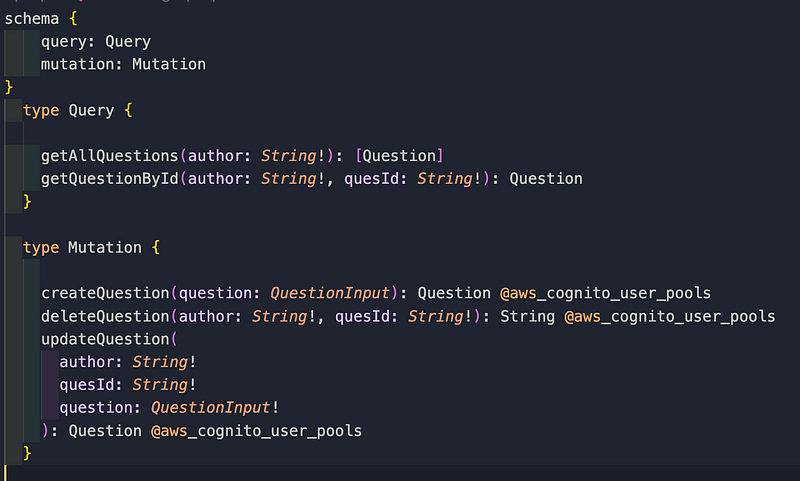
If you want access to the actual schema’s code, here's the link.
In the schema, queries fulfill HTTP GET requests while mutations fulfill requests such as POST, PUT, and DELETE. But remember, all GraphQL resolvers are POST requests.
Let's talk about the basic anatomy of some of these resolvers. In the getQuestionById query, it takes in the author and quesId parameters that are required(!) and of the string type. It then returns a Question that follows this type:
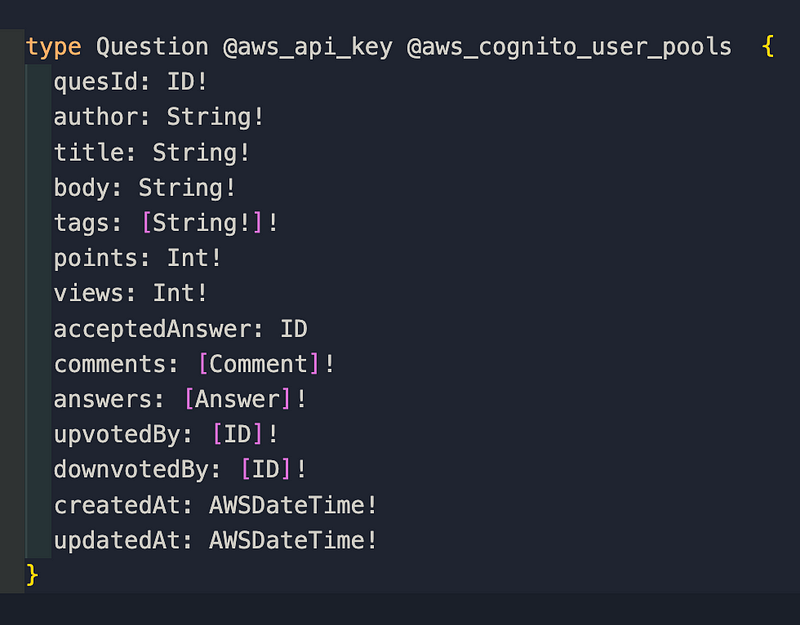
It may seem like a lot of information that a Question would hold, but this just describes ALL of the information. You can format your queries to only provide you necessary information if needed. But make sure when designing your schema, you are as thorough as you possibly can be because this schema acts as not only a guide but as another layer of self-validation, which points you in the right direction making for a smoother coding experience.
You probably noticed the @aws_api_key and @aws_cognito_user_pools too. These are AppSync directives that specify that the field should be AMAZON_COGNITO_USER_POOLS or API_KEY authorized. If you remember the last article, we made the API_KEY our default authorization method with AMAZON_COGNITO_USER_POOLS as an additional authorization method. This is because we want to allow our users to view questions freely while requiring them to log in for things such as creating, editing, and deleting a question.
With the basic backend setup finished, in our next segment, we will work on the actual lambdas and how to troubleshoot any errors that come up. Thanks for reading!