



Hey guys welcome to the final installment of my Stack Overflow Clone series! You can find it here on this website. Feel free to check it out, create a user (fake email is ok), and create and answer as many questions as you’d like! Since we finished our ERD and single-table design in the last installment, we’re going to talk about the API flow that requests data from our API and populates it on the client.
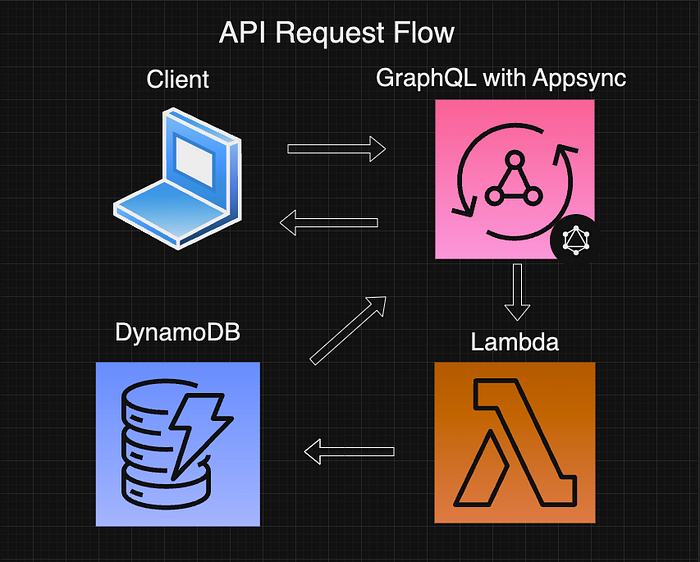
According to this diagram, the client will send a GraphQL request to AppSync which has a named resolver that is attached to our monolithic Lambda data source which also contains a ton of functions (main.ts) that handle CRUD functionality for all of my different entities (Author, Question, Answer, etc.). I would post the relevant info for the main.ts code here, but you can tell, it is pretty extensive. Just know that in this main.ts file, it waits for an AppSync event which has a fieldName and an object of arguments. The fieldName represents the AppSync resolver, GraphQL query or mutation, and the lambda function with the exact same name for simplicity’s sake. The argument object is the information that is needed to perform CRUD functionality for each of the entities. So in my main.ts file, based on the type of event that it receives, that’s when it knows what type of entity it’s working with and what to do with it.
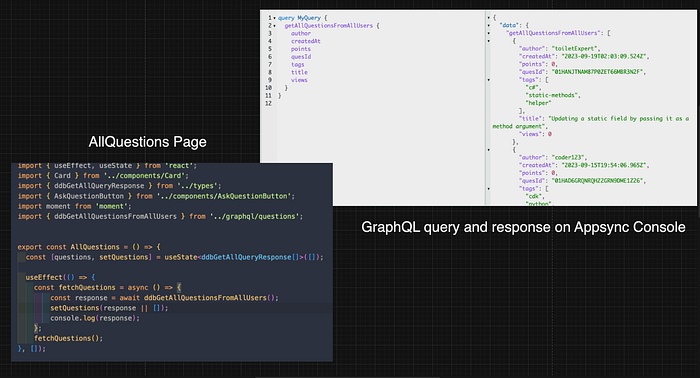
For example, if I wanted to view all the questions from all authors on my website, you would see in my code, that I import a function named ddbGetAllQuestionsFromAllUsers from my graphql directory, which sends a GraphQL query to Appsync which then triggers the getAllQuestionsFromAllUsers function from my main.ts handler, thus finally sending the information I requested in the query to my client.
Let's take a step back and talk about the step-by-step process of creating a lambda function in the backend and ultimately being able to use it in the frontend. This process is especially useful if you feel like you need to add more functionality to your project as you progress.
Steps
Create the Query or Mutation function in your
schema.graphqlfile while attaching the resolver to your data source in your backend cdk stack. Deploy.Verify that your resolver is attached to your data source by navigating to your schema in the Appsync console. This step is very important because I had assumed that doing the first step would automatically attach the resolver. As a result, whenever I would try to test the query, I would get a null response with no relevant logs depicting the error, resulting in days of…

3. Create your lambda function and test it with Cloudwatch logs. GraphQL with Appsync is especially helpful here because the response will always present the information that you request. No more, no less. Thanks to this, troubleshooting will be made a lot simpler. Most of my errors came from careless typos and type checking. Make sure you put console.logs everywhere just in case you stumble across a variable that ends up null in transition.
4. Once the lambda works as expected in the Appsync console, you know that the backend part of the code is functional. I created a graphql directory that stores all my functions that I would import into my frontend components. It also contains the queries needed to run the function.
5. Now, you have to think about how you will retrieve the information for the parameters to run your function/resolver. In most cases, I would require the author or quesId to run queries and mutations such as getById, delete, or update. I would just utilize the URLSearchParams to extract these values from the URL.
6. Again, just like you did in step 3, troubleshoot with your Cloudwatch logs. I’ve learned to appreciate this service because it is essentially what allowed me to learn the most. All the nights of stressing and moving on from error to new error essentially made me more comfortable in using all the other services. Learn to appreciate this step.
We can now go over my process of creating an API that creates questions.
schema.graphql

2. createQuestion is properly attached to the data source while deleteAuthor isn’t. If you need to attach another resolver, select VTL as the runtime and disable all the req/res templates.

3. In this example, for each question, I created 3 entries in the database with the intention of fulfilling these access patterns: getting all questions from all authors, getting all questions from one author, and getting all answers of a question. In this example, I used the batchWrite function which allows you to make multiple put and delete requests in one. However, if you have a conditional request like the one below and it evaluates to false, the rest of the batchWrite function will not run.
const createQuestion = async (questionInput: QuestionInput) => {
console.log(
`createQuestion invocation event: ${JSON.stringify(questionInput, null, 2)}`
);
const quesId = ulid();
const authId = ulid();
const formattedAuthor = questionInput.author ? questionInput.author.trim().replace(/\\s+/g, "") : "";
const question: Question = {
quesId,
author: formattedAuthor,
title: questionInput.title,
body: questionInput.body,
tags: questionInput.tags,
points: 0,
views: 0,
acceptedAnswer: null,
createdAt: new Date().toISOString(),
updatedAt: new Date().toISOString(),
upvotedBy: null,
downvotedBy: null
};
const authorParams = {
TableName: process.env.POSTS_TABLE,
Item: {
PK: `AUTHORS`,
SK: `AUTHOR#${formattedAuthor}`,
authId,
createdAt: new Date().toISOString(),
type: "author",
authName: formattedAuthor,
},
}
// when creating a question, find if the author entity has already been created
// if not, create the author entity. If so, bypass this step and
// create the question
try {
const authorExists = await docClient.query({
TableName: process.env.POSTS_TABLE,
KeyConditionExpression: "#PK = :PK AND begins_with(#SK, :sk_prefix)",
ExpressionAttributeNames: {
"#PK": "PK",
"#SK": "SK",
},
ExpressionAttributeValues: {
":PK": `AUTHORS`,
":sk_prefix": `AUTHOR#${formattedAuthor}`,
},
})
.promise();
if (authorExists.Count > 0) {
console.log(`author already exists: ${authorParams.Item.authName}`);
} else {
const response = await docClient.put(authorParams).promise();
console.log(`Successfully added author: ${authorParams.Item.authName}`);
console.log(response);
}
} catch (err) {
console.error(`Error processing author: ${formattedAuthor}`);
console.error(err);
}
const params = {
RequestItems: {
"TableName": [
{
PutRequest: {
Item: {
PK: `QUESTIONS`,
SK: `QUESTION#${quesId}`,
type: 'question',
...question,
},
},
},
{
PutRequest: {
Item: {
PK: `QUESTION#${quesId}`,
SK: `QUESTION#${quesId}`,
type: 'question',
...question,
},
},
},
{
PutRequest: {
Item: {
PK: `AUTHOR#${formattedAuthor}`,
SK: `QUESTION#${quesId}`,
type: 'question',
...question,
},
},
},
],
},
ReturnConsumedCapacity: "TOTAL",
};
try {
const data = await docClient.batchWrite(params).promise();
console.log(`Created question: ${JSON.stringify(question, null, 2)}`);
if(data) {
createTag(question);
}
return question;
} catch (err) {
console.log(`DynamoDB Error: ${JSON.stringify(err, null, 2)}`);
throw err;
}
};
export default createQuestion;
4. As you can see from the code, I am passing a question object that is typechecked twice by GraphQL’s (QuestionInput) and the SaveQuestionProps type. I then require that only logged-in users can run this API through the specified authMode, and then I return the response.
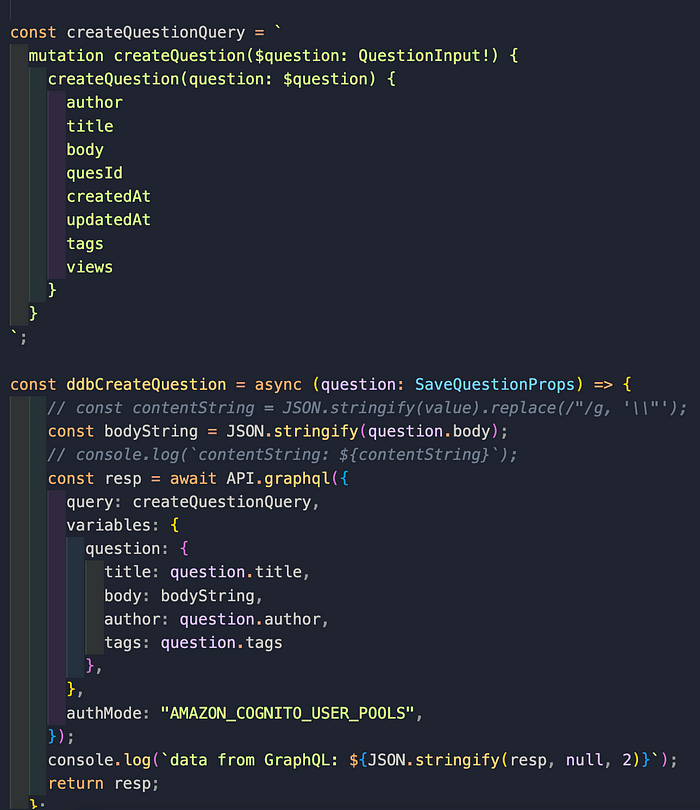
5. In my CreateQuestion.ts file, I create the question object by extracting the current logged-in user’s name and then having the user provide the rest of the information through my form. You can see the code here.
6. Here is an example of a successful log. Since I have completed the project, every time I create a question, my logs describe the additional processes such as creating the author and tag entity if it doesn’t already exist and creating each tag listed and connecting it to the question.
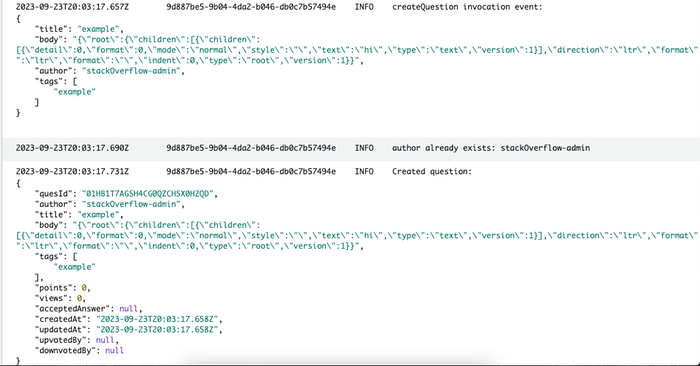
The body may look weird, but that just represents a way of storing rich text content in a database so that it can be retrieved and displayed as formatted text when requested. Here is an example:
After these 6 steps, if you were like me, you should experience an arduous rollercoaster ride with a euphoric finale but most importantly, you’ll have a functional API. Thanks for checking out the blogs! I hope you learned as much as I had during this journey and I’ll see you in the next blog post :D